プレスリリース
「SORACOM Partner Spaceアワード 2023」 アステリアが「SPSエバンジェリスト・オブ・ザ・イヤー」を受賞

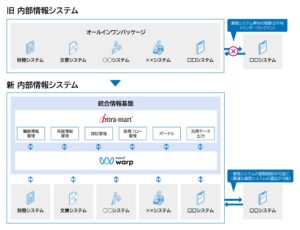
ノーコード技術で業務の自動化を支援する「データ連携ツール」
多様な働き方に合う、さまざまなシーンで情報を閲覧・共有できる「デジタルコンテンツプラットフォーム」
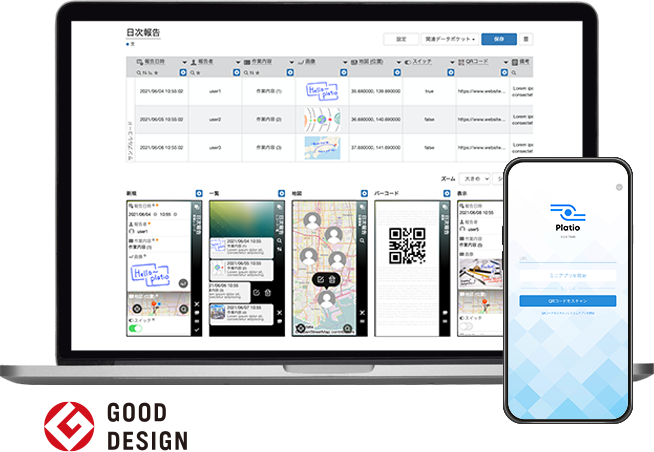
現場に合った業務アプリを簡単に作成できる「モバイルアプリ作成ツール」

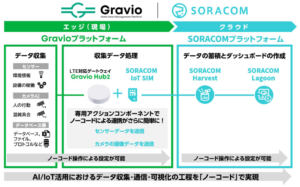
ノーコードでAIやIoTを簡単に実現する「統合型エッジプラットフォーム」

私たちアステリアは、世界中の輝く企業や人を「つなぐ」エキスパートとして、企業の価値創造を飛躍的に高める製品とサービスを開発・提供し、社会に貢献してまいります。

投資家の皆様へ。私たちは、豊富な実績と卓越した技術力を活かして社会の進化を加速する製品・サービスをお客様にお届けしてまいります。

アステリアは1998年に国内初のXML専業ソフトウェア会社として設立。企業内の多種多様なコンピューターやデバイスの間を接続するソフトウェアやサービスを開発・販売しております。

決算説明会や技術情報など動画で紹介しています。